


Kiedy warto rozważyć zakup nieruchomości?
Zakup nieruchomości to zawsze wielka decyzja, która wymaga starannego przemyślenia i analizy. Bez względu na to, czy jesteś pierwszym nabywcą czy doświadczonym inwestorem, istnieją pewne czynniki, które warto wziąć pod...

Jakie są obowiązki notariuszy w procesie zawierania umów?
W świetle prawa polskiego, notariusz pełni kluczową rolę w procesie zawierania różnorodnych umów. Jego obecność jest wymagana w wielu przypadkach, by zapewnić prawomocność dokumentów oraz bezpieczeństwo transakcji. W poniższym artykule...

Kiedy zapisać dziecko do alergologa?
Decyzja o skierowaniu dziecka do alergologa to ważny krok w trosce o jego zdrowie. Alergie są jednym z najczęstszych schorzeń przewlekłych u dzieci i mogą mieć różnorodne objawy, od łagodnych...

Nagrobki granitowe – kiedy warto się na nie zdecydować?
Wybór odpowiedniego nagrobka to decyzja, która wpływa na pamięć o zmarłym przez wiele pokoleń. Granit, jako jeden z najczęściej wybieranych materiałów, oferuje trwałość oraz estetykę, które są kluczowe przy wyborze...

Rola NFZ w zapewnieniu wysokiej jakości opieki ortodontycznej dla dzieci
Ortodoncja dla dzieci to nie tylko kwestia estetyki, ale również zdrowia i komfortu młodych pacjentów. W dzisiejszych czasach, dzięki Narodowemu Funduszowi Zdrowia (NFZ), coraz więcej dzieci ma dostęp do wysokiej...

Pomoc w wysyłaniu paczek – co wchodzi w zakres takich usług?
Współczesny rynek usług kurierskich oferuje szeroki zakres opcji, które ułatwiają zarówno osobom prywatnym, jak i firmom wysyłanie paczek krajowych i międzynarodowych. Usługi te są coraz bardziej dostosowane do indywidualnych potrzeb...

Jak wygląda praca agencji detektywistycznej?
W dzisiejszych czasach agencje detektywistyczne cieszą się rosnącym zainteresowaniem zarówno ze strony klientów indywidualnych, jak i biznesowych. Ich działalność, otoczona aurą tajemniczości i niejednokrotnie dramatyzmu, wydaje się być pełna niewiadomych....

Jak zadbać o drogi moczowe?
Drogi moczowe odgrywają kluczową rolę w eliminacji toksyn z organizmu oraz utrzymaniu równowagi wodno-elektrolitowej. Zdrowe funkcjonowanie tego układu jest niezwykle istotne dla ogólnego stanu zdrowia. Istnieje wiele prostych sposobów, aby...

Butle gazowe turystyczne – kiedy warto zakupić?
Podróżowanie z namiotem, camperem czy też wędrowanie po bezdrożach wymaga odpowiedniego przygotowania, w tym zapewnienia sobie dostępu do wygodnego źródła energii. W takich sytuacjach na scenę wkraczają butle gazowe turystyczne....

Jakie są rodzaje usług notarialnych?
Usługi notarialne stanowią istotny element funkcjonowania społeczeństwa, pełniąc nie tylko rolę potwierdzania ważności dokumentów, lecz także świadcząc wsparcie w rozmaitych sprawach prawnych. Notariusze, wyposażeni w wiedzę prawną i umiejętności komunikacyjne,...

Ekologiczne opakowania tekturowe – z czego są wykonywane?
Obecnie, coraz większy nacisk kładzie się na ochronę środowiska i ograniczanie negatywnego wpływu działalności człowieka na ekosystemy. Jednym z obszarów, który przyciąga coraz większą uwagę, jest problematyka opakowań, zwłaszcza w...

Z jakimi sprawami może nam pomóc geodeta?
Współczesny świat stawia przed nami wiele wyzwań związanych z planowaniem, budowaniem i użytkowaniem przestrzeni. W tych procesach kluczową rolę odgrywa geodezja, a geodeta – specjalista posiadający wiedzę z zakresu geodezji...

Systemy przechowywania narzędzi – jakie mają zalety?
W dzisiejszych czasach posiadanie odpowiedniego miejsca do przechowywania narzędzi staje się coraz bardziej istotne, zwłaszcza dla pasjonatów majsterkowania oraz profesjonalnych rzemieślników. Systemy przechowywania narzędzi są nie tylko praktyczne, ale także...

Cena wynajmu autokaru z kierowcą – ile trzeba zapłacić?
Planujesz wypożyczyć autokar razem z kierowcą? Zastanawiasz się nad kosztami takiej obsługi? Przyglądamy się opłatom za wynajem autokaru z kierowcą, uwzględniając różne czynniki, które wpływają na ostateczną cenę! (więcej…)

Dlaczego jeansy to must have w każdej męskiej szafie?
Jeansy, od ponad wieku stanowiące podstawę mody ulicznej, ewoluowały z roboczego uniformu do uniwersalnego elementu garderoby. Ich niezachwiana popularność wynika z wygody, trwałości oraz wszechstronności, co czyni je nieodłącznym elementem...

Producent kartonów z tektury falistej – na czym polega jego praca?
W dzisiejszych czasach opakowania kartonowe są wszechobecne w naszym życiu codziennym. Od paczek dostarczanych przez kuriera po produkty na półkach sklepowych – trudno wyobrazić sobie funkcjonowanie wielu branż bez nich....

Jak przebiega proces montażu i demontażu mobilnych żurawi wieżowych?
W dzisiejszych czasach, kiedy budownictwo rozwija się w zaskakującym tempie, mobilne żurawie wieżowe stanowią kluczowy element w zakresie efektywności i elastyczności na placach budowy. Ich zdolność do szybkiego montażu i...

Co warto wiedzieć o pielęgnacji jabłoni Reneta?
Wprowadzenie do pielęgnacji jabłoni Reneta zapewnia unikalną perspektywę na jedno z najbardziej cenionych gatunków drzew owocowych. Charakteryzująca się wyjątkowym smakiem i trwałością owoców, jabłoń Reneta wymaga specjalnej troski, aby mogła...

Z jakimi dodatkami podawać sushi?
Sushi, japońska potrawa składająca się głównie z ryżu przyprawionego octem ryżowym oraz różnorodnych dodatków takich jak surowe lub wędzone ryby, owoce morza, warzywa czy nawet tropikalne owoce, zyskała na popularności...

Rozwód bez orzekania o winie
Współczesne społeczeństwo coraz częściej zmierza ku rozwiązaniom, które pozwalają zakończyć małżeństwo w sposób cywilizowany i pozbawiony negatywnych emocji. Rozwód bez orzekania o winie stanowi jedną z takich opcji, pozwalając małżonkom...

Jakie są sposoby na redukcję zapylenia w zakładach produkcyjnych?
Zapylenie w zakładach produkcyjnych stanowi nie tylko zagrożenie dla zdrowia pracowników, ale także może negatywnie wpływać na jakość produktów oraz środowisko. Wprowadzenie skutecznych metod redukcji zapylenia jest niezwykle istotne dla...

Czym zajmuje się producent farb przemysłowych?
Współczesny przemysł wymaga stosowania specjalistycznych rozwiązań, które nie tylko zwiększają wydajność produkcji, ale także zapewniają długotrwałą ochronę i estetykę produktów. W tym kontekście kluczową rolę odgrywają farby przemysłowe, które są...

Co wchodzi w skład systemów zabezpieczeń elektrycznych?
W dobie wszechobecnej cyfryzacji oraz rosnącego zapotrzebowania na bezpieczeństwo, systemy zabezpieczeń elektrycznych stanowią kluczowy element ochrony zarówno w sektorze prywatnym, jak i przemysłowym. Ich rola nie ogranicza się wyłącznie do...

Jakie są najczęstsze błędy przy oddawaniu auta na złom?
Oddawanie samochodu na złom to często ostatni etap życia pojazdu, który z różnych powodów nie nadaje się już do użytku. Może to być wynik awarii, wypadku lub po prostu starości...

Koszulki polo z własnym nadrukiem – sposób na wyróżnienie się
Koszulki polo z własnym nadrukiem to doskonały sposób na wyróżnienie się w tłumie i zaprezentowanie swojego indywidualnego stylu. Coraz więcej firm, zarówno małych lokalnych przedsiębiorstw, jak i dużych korporacji, decyduje...

Czy pellet jest bezpieczny?
W obliczu rosnącej popularności alternatywnych źródeł energii, wiele osób zastanawia się nad bezpieczeństwem i efektywnością dostępnych opcji. Pellet, będący jednym z coraz częściej wybieranych rozwiązań do ogrzewania domów, wzbudza zainteresowanie...

Doradca kredytowy w Warszawie: Kompleksowy przewodnik po usługach i korzyściach
Doradca kredytowy Warszawa to specjalista, który pomaga klientom w znalezieniu najlepszych ofert kredytowych dostępnych na rynku. Współpracując z doradcą kredytowym, można liczyć na profesjonalne wsparcie na każdym etapie procesu kredytowego,...

Rodzaje policyjnych alkomatów – co warto wiedzieć?
Alkomaty policyjne stanowią nieodłączny element narzędzi wykorzystywanych przez służby policyjne w kontroli bezpieczeństwa na drogach. To zaawansowane urządzenia pomiarowe, które pełnią kluczową funkcję w identyfikowaniu kierowców prowadzących pojazdy pod wpływem...

Rękawice termiczne: Kompleksowy przewodnik po ich cechach, zastosowaniu i zaletach
Rękawice termiczne to niezbędny element wyposażenia dla osób pracujących w ekstremalnych warunkach, a także dla tych, którzy chcą chronić swoje dłonie przed niskimi temperaturami w codziennym życiu. W tym artykule...

Co można kupić w kwiaciarni?
Kwiaciarnie od dawna są miejscami, gdzie piękno natury spotyka się z artystycznym kunsztem. Są one nie tylko sklepami, ale przestrzeniami pełnymi barw, zapachów i emocji. W kwiaciarniach znajdziemy nie tylko...

Wakacje w Grecji – miejsca, które trzeba zobaczyć!
Wybierasz się do Grecji? Pragniesz spędzić urlop w tym malowniczym kraju na południu Europy? Powinieneś dobrze się przygotować i poznać najciekawsze regiony, które warto odwiedzić. Grecja zarówno w części wyspiarskiej,...

Jak przebiega odwadnianie wykopów?
Odwadnianie wykopów to istotna część procesów budowlanych i inżynieryjnych, mająca na celu usunięcie nadmiaru wody z terenu budowy, co jest kluczowe dla bezpieczeństwa i efektywności prac. Proces ten obejmuje różnorodne...
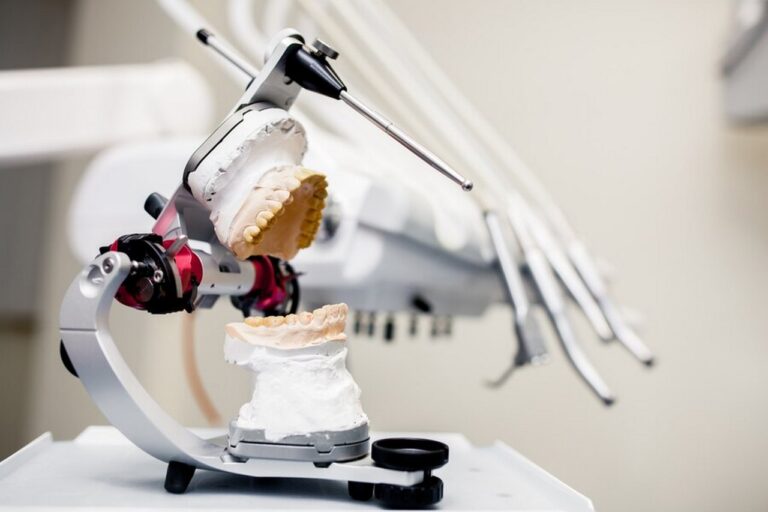
Protetyk – kiedy wybrać się do niego na wizytę?
Zadbana i zdrowa jama ustna odgrywa kluczową rolę w ogólnym samopoczuciu i zdrowiu człowieka. Wielu z nas bagatelizuje drobne problemy z zębami lub protezami, nie zdając sobie sprawy z potencjalnych...

Nożyce do żywopłotu – jakie są ich rodzaje?
W dzisiejszych czasach, kiedy coraz więcej osób ceni sobie piękno i estetykę swoich ogrodów, odpowiedni dobór narzędzi do pielęgnacji roślinności staje się kluczowy. Jednym z niezbędnych narzędzi w każdym ogrodzie...

Jak producent oleju słonecznikowego dystrybuuje swoje wyroby?
Dystrybucja produktów spożywczych, w tym oleju słonecznikowego, jest niezmiernie istotnym etapem w łańcuchu dostaw. Producent oleju słonecznikowego angażuje się w szereg strategicznych procesów, aby zapewnić, że ich produkt trafia do...

Jak powinna być wykonana pościel dziecięca?
Wybór pościeli dla najmłodszych to zadanie, które wymaga szczególnej uwagi i staranności. Nie tylko ze względu na estetykę i dopasowanie do pokoju dziecięcego, ale przede wszystkim ze względu na zdrowie...

Jakie są najważniejsze cechy dobrej taśmy samoprzylepnej?
Taśmy samoprzylepne są niezastąpionym narzędziem w życiu codziennym i przemyśle, umożliwiając skuteczne łączenie, pakowanie, czy nawet dekorowanie. Kluczem do efektywnego wykorzystania tych produktów jest jednak ich właściwy wybór, biorąc pod...
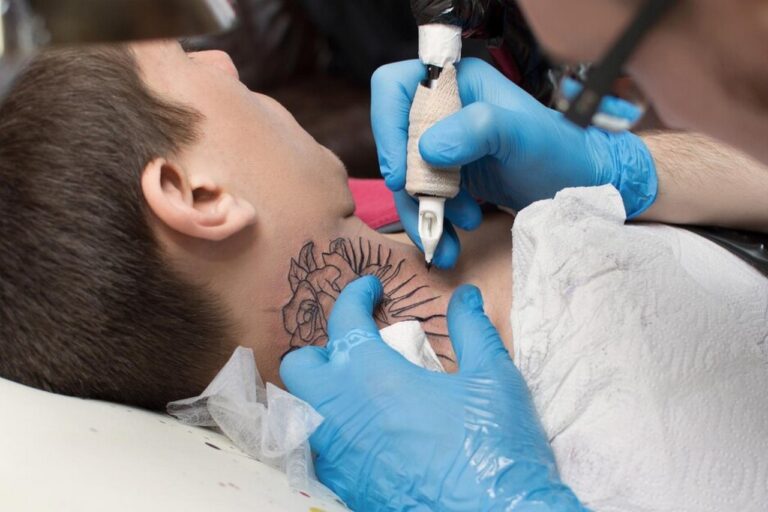
Jakie zalety ma stosowanie kremu znieczulającego do tatuażu?
Tatuaże stały się popularną formą wyrazu indywidualności. Dla wielu osób jest to sposób na wyrażenie swoich pasji, uczuć i przekonań. Jednak proces ich wykonywania może być bolesny i nieprzyjemny. Warto...

Zaproszenia ślubne na zamówienie – jakie mają zalety?
W dniu ślubu każda para pragnie, aby każdy element uroczystości odzwierciedlał ich wyjątkowość. Nie bez powodu coraz więcej przyszłych małżonków decyduje się na zaproszenia ślubne na zamówienie. Ten trend zdobywa...

Jakie substancje można przechowywać w zbiornikach ciśnieniowych ze stali nierdzewnej?
Zbiorniki ciśnieniowe pełnią kluczową rolę w przechowywaniu i transportowaniu różnorodnych substancji chemicznych oraz gazów. Wśród wielu dostępnych materiałów konstrukcyjnych, stal nierdzewna cieszy się rosnącym uznaniem ze względu na swoją odporność...

Czy osuszanie ścian po zalaniu można zrealizować samodzielnie?
Zalanie pomieszczenia, czy to wynikające z awarii instalacji wodnej czy z przyrody, może być nie tylko frustrujące, ale także prowadzić do poważnych uszkodzeń strukturalnych. Jednym z kluczowych aspektów, które należy...

Dlaczego należy przeprowadzać przeglądy gaśnic?
W świecie, w którym bezpieczeństwo odgrywa kluczową rolę, nie można bagatelizować roli gaśnic jako środków ochrony przeciwpożarowej. Gaśnice są nieodzownym elementem wyposażenia, mającym na celu skuteczną likwidację zagrożeń pożarowych. Jednak...

Transport przy przeprowadzkach – jak go zorganizować?
Przeprowadzka to moment pełen wyzwań, wymagający nie tylko siły fizycznej, ale przede wszystkim odpowiedniej organizacji. Kluczowym aspektem, który decyduje o sprawnym przebiegu całego procesu, jest efektywny transport. Niezależnie od tego,...

Standardy kalibracji alkomatów na świecie – międzynarodowe organizacje i wytyczne
Kalibracja alkomatów odgrywa ważną rolę w zapewnieniu precyzyjnych i rzetelnych wyników pomiarów trzeźwości kierowców na całym świecie. Przyjrzyjmy się jednak w jaki sposób standardy kalibracji są ujednolicane oraz jaki przynoszą...

Jak dobrać odpowiedni drążek do szafy?
Wybór odpowiedniego drążka do szafy jest kluczowym elementem organizacji garderoby. Nie tylko musi on pasować do wymiarów i stylu szafy, ale również wytrzymać ciężar zawieszonych ubrań. W tym artykule, przedstawiamy,...

Do czego służą przeciągarki ręczne linowe?
W dzisiejszym świecie, w którym praca manualna nieustannie współgra z zaawansowaną technologią, narzędzia takie jak przeciągarki ręczne linowe stanowią niezastąpiony element wyposażenia. To wyjątkowe urządzenia, pozornie skromne w swoim wyglądzie,...

Z czego mogą być wykonane stojaki do szyb?
Stojaki do szyb są kluczowym elementem wyposażenia warsztatów i zakładów zajmujących się ich obróbką oraz montażem. W zależności od potrzeb i specyfiki pracy mogą przyjmować różne formy i być wykonane...

Jak zaplanować projekt budowlany?
Planowanie projektu budowlanego to skomplikowany proces, wymagający dokładnej analizy i przemyślanej organizacji. Niezależnie od tego, czy mamy do czynienia z małą rozbudową domu, czy dużym przedsięwzięciem komercyjnym, kluczowe jest uwzględnienie...

Jakie badania wykonuje logopeda?
Współczesna medycyna rozumie, jak ważne jest wcześniejsze wykrywanie i leczenie problemów z mową. Dzięki temu możliwe jest uniknięcie wielu komplikacji w późniejszym życiu pacjenta. Logopeda jest specjalistą, który zajmuje się...
Jakie rękawice są odpowiednie do ćwiczeń z workiem treningowym bokserskim?
Wybierając rękawice do treningu z workiem bokserskim, ważne jest, aby dokładnie przemyśleć swoje potrzeby i rodzaj treningu, jaki planujesz przeprowadzać. Pełnią one kluczową rolę w ochronie dłoni i nadgarstków, zapewniając...

Jak prawidłowo łączyć rury wentylacyjne?
Wentylacja w budynkach jest nieodłącznym elementem, gwarantującym świeże powietrze oraz odpowiednią cyrkulację powietrza. Jednakże wiele osób zadaje sobie pytanie, czy rury tego systemu muszą być izolowane. Poniższy artykuł pomoże rozwiać...

Drapak dla kota: Kompleksowy przewodnik po wyborze i ustawieniu idealnego drapaka
Drapak dla kota to niezbędny element wyposażenia każdego domu, w którym mieszka kot. Właściwy wybór drapaka może znacznie wpłynąć na komfort życia naszego pupila, a także na stan naszych mebli...

Pompa ciepła – dlaczego warto?
W dzisiejszych czasach, kiedy dbałość o środowisko naturalne oraz oszczędność energii stają się coraz ważniejsze, pompy ciepła zyskują na popularności. To ekologiczne i efektywne rozwiązanie pozwalające na ogrzewanie i chłodzenie...

Do jakich celów używana jest płyta blacharska?
Płyta blacharska to wszechstronny materiał, który od dawna znajduje szerokie zastosowanie w wielu dziedzinach. Niezależnie od tego, czy jesteś profesjonalnym blacharzem, czy po prostu interesujesz się pracami remontowymi, warto poznać...

Jak szukać dobrych ofert mieszkania na sprzedaż?
W czasach, kiedy rynek nieruchomości jest coraz bardziej konkurencyjny, znalezienie idealnego mieszkania na sprzedaż może być zadaniem wymagającym. Kluczowym jest wiedzieć, jak skutecznie poszukiwać, porównywać oferty i podejmować mądre decyzje....

Jak wygląda recykling odpadów metalowych?
W dzisiejszych czasach, kiedy troska o środowisko staje się coraz ważniejsza, recykling odpadów metalowych odgrywa kluczową rolę w zmniejszaniu naszego wpływu na planetę. Proces ten nie tylko pomaga w ochronie...
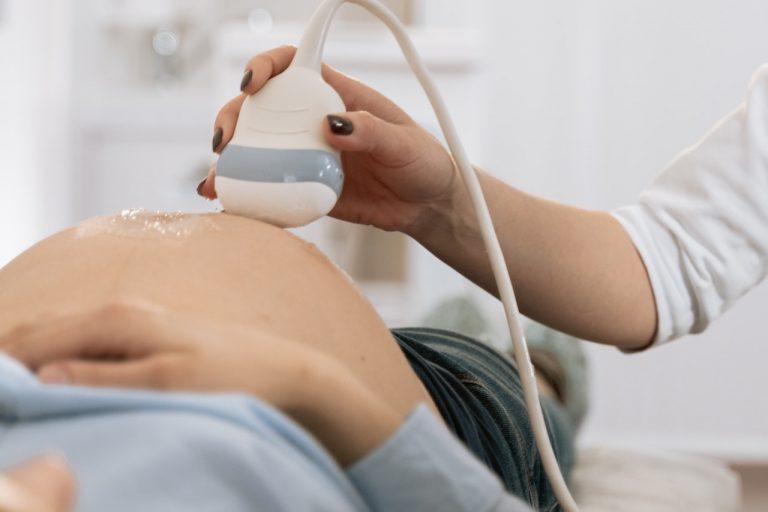
USG ciąży – jak przygotować się do badania?
Ciąża to jedno z najważniejszych okresów w życiu każdej kobiety, pełne emocji, pytań i oczekiwań. Odpowiednia opieka prenatalna jest kluczowa dla zdrowia zarówno matki, jak i dziecka. Jednym z najważniejszych...

Jak wybrać odpowiednie folie ogrodnicze?
Ogrodnictwo to pasjonujące hobby, które wymaga uwagi i troski. Jednym z kluczowych elementów skutecznej opieki nad roślinami w ogrodzie są folie ogrodnicze. Są to produkty, które pomagają w kontrolowaniu warunków...

Playmobil dla dziewczynek – co warto wiedzieć o tych zabawkach?
Zabawki odgrywają istotną rolę w rozwoju dzieci, umożliwiając im rozwijanie wyobraźni, kreatywności oraz umiejętności społecznych. Jednym z popularnych wyborów w kategorii zabawek dla dzieci są zestawy Playmobil, które oferują szeroki...

Fotowoltaika w Gdańsku: Kompleksowy przewodnik po instalacjach fotowoltaicznych
Fotowoltaika Gdańsk to temat, który zyskuje na popularności w ostatnich latach. Coraz więcej osób decyduje się na inwestycję w panele słoneczne, aby korzystać z energii odnawialnej i obniżyć rachunki za...